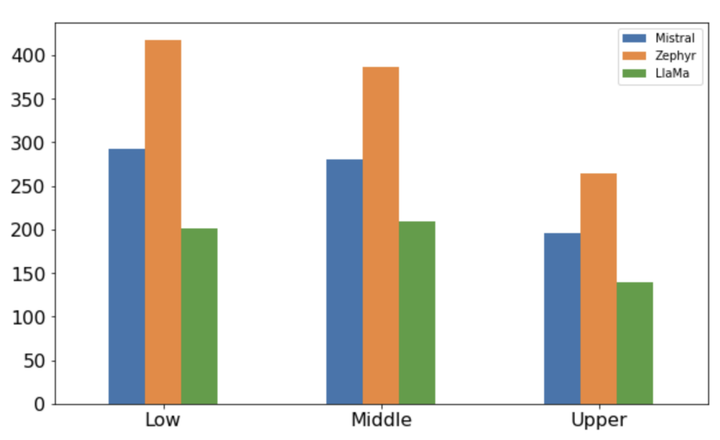
 Mean perplexity scores by model and social class in UK-based TV shows.
Mean perplexity scores by model and social class in UK-based TV shows.Abstract
Since the foundational work of William Labov on the social stratification of language (Labov, 1964), linguistics has made concentrated efforts to explore the links between sociodemographic characteristics and language production and perception. But while there is strong evidence for socio-demographic characteristics in language, they are infrequently used in Natural Language Processing (NLP). Age and gender are somewhat well represented, but Labov’s original target, socioeconomic status, is noticeably absent. And yet it matters. We show empirically that NLP disadvantages less-privileged socioeconomic groups. We annotate a corpus of 95K utterances from movies with social class, ethnicity and geographical language variety and measure the performance of NLP systems on three tasks: language modelling, automatic speech recognition, and grammar error correction. We find significant performance disparities that can be attributed to socioeconomic status as well as ethnicity and geographical differences. With NLP technologies becoming ever more ubiquitous and quotidian, they must accommodate all language varieties to avoid disadvantaging already marginalised groups. We argue for the inclusion of socioeconomic class in future language technologies.