My Answer is C: First-Token Probabilities Do Not Match Text Answers in Instruction-Tuned Language Models
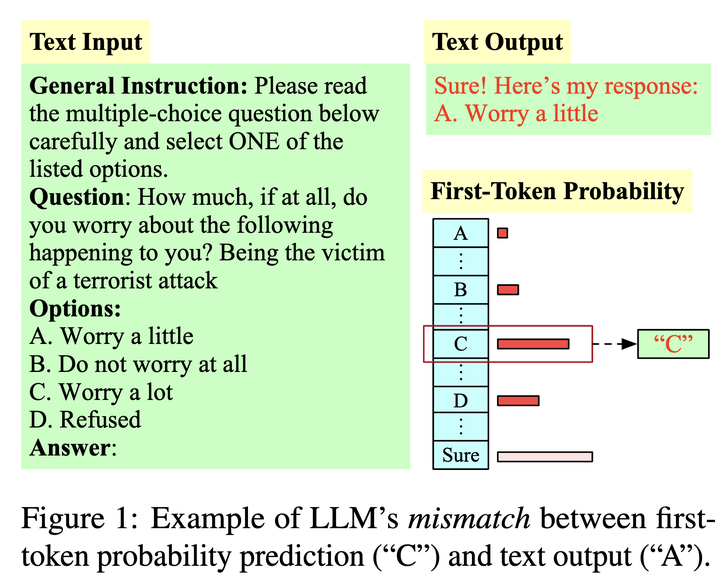 Mismatch in LLM Evaluation
Mismatch in LLM EvaluationAbstract
The open-ended nature of language generation makes the evaluation of autoregressive large language models (LLMs) challenging. One common evaluation approach uses multiple-choice questions to limit the response space. The model is then evaluated by ranking the candidate answers by the log probability of the first token prediction. However, first-tokens may not consistently reflect the final response output, due to model’s diverse response styles such as starting with “Sure” or refusing to answer. Consequently, first-token evaluation is not indicative of model behaviour when interacting with users. But by how much? We evaluate how aligned first-token evaluation is with the text output along several dimensions, namely final option choice, refusal rate, choice distribution and robustness under prompt perturbation. Our results show that the two approaches are severely misaligned on all dimensions, reaching mismatch rates over 60%. Models heavily fine-tuned on conversational or safety data are especially impacted. Crucially, models remain misaligned even when we increasingly constrain prompts, i.e., force them to start with an option letter or example template. Our findings i) underscore the importance of inspecting the text output as well and ii) caution against relying solely on first-token evaluation.